ISSUE
데이터 리터러시, 그리고 통계 리터리시
윤석용 | 명지대 AI빅데이터융합연계교수

리터러시(Literacy)라는 용어 자체는 다소 생경하지만, 단어를 이해하는 데는 그렇게 어렵지 않다. 케임브리지 영영사전에서 리터러시는 “읽고 쓰는 능력(the ability to read and write)”으로 정의되어 있다. 좀 더 풀어 보면, 문장을 읽어 이해하는 독해력(讀解力)과 의사를 표현하기 위한 문장력(文章力)이라고 할 수 있고, 최근에는 독해력을 문해력(文解力)으로 표현하기도 한다. 그런데 문해력은 읽고 이해하는 능력을 넘어 데이터를 찾고, 데이터를 분석하여 이해하고, 인사이트를 발견하고, 여러 사람과 소통하고, 도구를 이용한 계산 및 통계처리 등을 포함하는 조금은 더 포괄적인 역량을 말한다.
최근 인터넷에서 많이 회자되었던 ‘심심한 사과’, ‘사흘’ 등의 표현이 바로 문해력과 관련된 이슈의 일면이라고 할 수 있는데, 2022년 EBS가 조사한 문해력 수준 진단 결과, 조사대상자의 27.5%가 문장 이해에 어려움이 있다는 것이다. 독서와 사고보다는 직관적이고 단편적인 동영상과 앞뒤 문맥 없이 축소된 단어들에 익숙한 인터넷 시대의 단면이기도 하다. 국립국어원의 우리말샘에서 보면 새롭게 등록된 디지털 리터러시, 미디어 리터러시라는 단어가 있는 데, 여기서 디지털 리터러시를 이렇게 정의하고 있다. “디지털 시대에 필수적으로 요구되는 정보의 이해 및 표현 능력”. 20세기 들어 인터넷의 출현은 우리 모두의 삶을 빠른 속도 위에 올려놓았다. 수일 또는 수주에 걸려 전달되던 편지가 키보드의 클릭만으로 수초 내에 전달되고, 데이터가 쌓여가는 속도 또한 과거와는 비교가 되지 못한다.
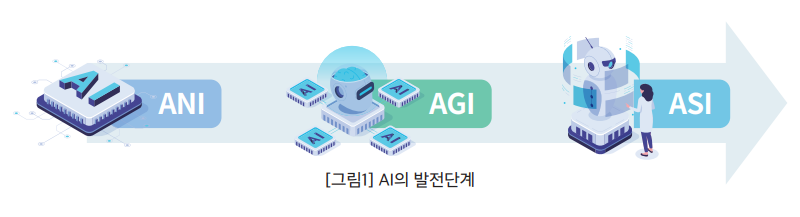
아직도 인공지능(AI)이라고 하면 SF 영화 속 로봇을 떠올릴 수도 있지만, 이제 AI는 현실이 되어 누구나 쉽게 경험할 수 있는 시대가 되었다. AI는 보통 세 단계로 나누어진다.
1단계인 ANI(Artificial Narrow Intelligence)는 데이터분석, 기계학습 알고리즘 등으로 무장하여 AI의 맛을 보여준 빅데이터 시대를 열었다.
2단계인 AGI(Artificial General Intelligence)는 특정 도메인에 국한하지 않는 인간과 유사한 일반적 지능을 갖춘 인공지능으로 아직은 멀리 있는 공상 과학 속의 단계로 생각했지만, ChatGPT의 출현은 AGI로 들어가는 초입일 수 있다고 많은 학자가 이야기하고 있다.
3단계는 레이 커즈와일(Ray Kurzweil) 이 이야기한 특이점의 시대, 즉 ASI (Artificial Super Intelligence)로서, 강력한 지능 체계를 갖추고 스스로 목표를 설정하여 지식을 강화하는, 말 그대로 영화 속 인공지능의 세상이다.
이제 AI는 강 건너의 이야기가 아닌 우리 시대의 주류가 되어가고 있고, 여기에 맞는 정보의 이해 및 표현 능력이 필요하다. 이것이 지금의 리터러시라고 할 수 있다.
지금의 AI는 수십 년 전의 인공지능과 접근방식이 전혀 다르다. 즉 프로세스의 논리적 구현이 아닌, 데이터 기반의 학습으로 ChatGPT를 통하여 경험한 것처럼 빅데이터의 활용과 컴퓨팅 파워를 이용하여 AI를 구현함으로써 AI의 무한한 능력의 확대를 보여 주고 있다. 따라서 지금은 AI의 기반이라 할 수 있는 데이터와 데이터 분석으로 들어가 데이터 리터러시를 이해하는 것이 무엇보다 중요한 시점이 되었다.

데이터의 존재만으로 데이터의 가치를 이야기하는 것은, 금이 매장된 산의 존재만으로는 그 가치를 알 수 없고 채굴을 통해서만이 금의 절대적 가치 평가가 가능하듯이, 데이터도 존재만으로는 제한적인 의미를 갖지만, 데이터 분석을 통해 인사이트를 찾는다면 데이터의 절대적 가치를 평가받을 수 있다.
데이터를 분석하기 위해서는 많은 전문적 지식이 요구되는데, 이러한 전문가를 데이터과학자(Data Scientist), 데이터분석가(Data Analyst)라고 한다. 그러나 이러한 전문가에게 데이터 리터러시를 이야기하는 것은 대장장이에게 쇠메의 사용 방법을 이야기하는 것과 같다. 데이터 리터러시는 자기의 본연의 업무가 있고, 이를 수행하면서 발생한 데이터를 스스로 분석하고 인사이트를 찾아 활용 할 수 있는 역량으로, 데이터 분석 전문가를 제외한 우리 대다수라고 할 수 있다. 이를 시티즌 데이터 사이언티스트(Citizen Data Scientist, CDS) 라고 부른다.
CDS가 갖춰야 할 데이터 리터러시를 정리하면,
❶ 첫째, 자신의 데이터를 수집하고 분석할 수 있는 역량이다. 수행하는 업무에서 발생하는 데이터의 가치를 인식하고, 이를 의미 있게 수집·저장할 수 있고, 수집된 데이터를 이용하여 통계분석, 데이터시각화 등 의 탐색적데이터분석(EDA)을 수행하고, 필요시 Orange3와 같은 CDS 도구를 이용하여 예측모형을 쉽게 만들어 업무에 적용해 보는 것이다.ᅠ
❷ 둘째, 데이터 분석 결과로 보고서를 만들어 의사소통에 활용하거나 Streamlit, Shiny 등의 간단한 도구를 이용하여 데이터 분석 결과를 시스템화해보는 것이다. CDS 입장에서 기계학습·딥러닝·시스템화가 가능할 수 있을지 의문을 품을 수도 있지만, CDS 도구는 바로 이러한 상황을 쉽게 풀어주는 툴이라고 할 수 있다.
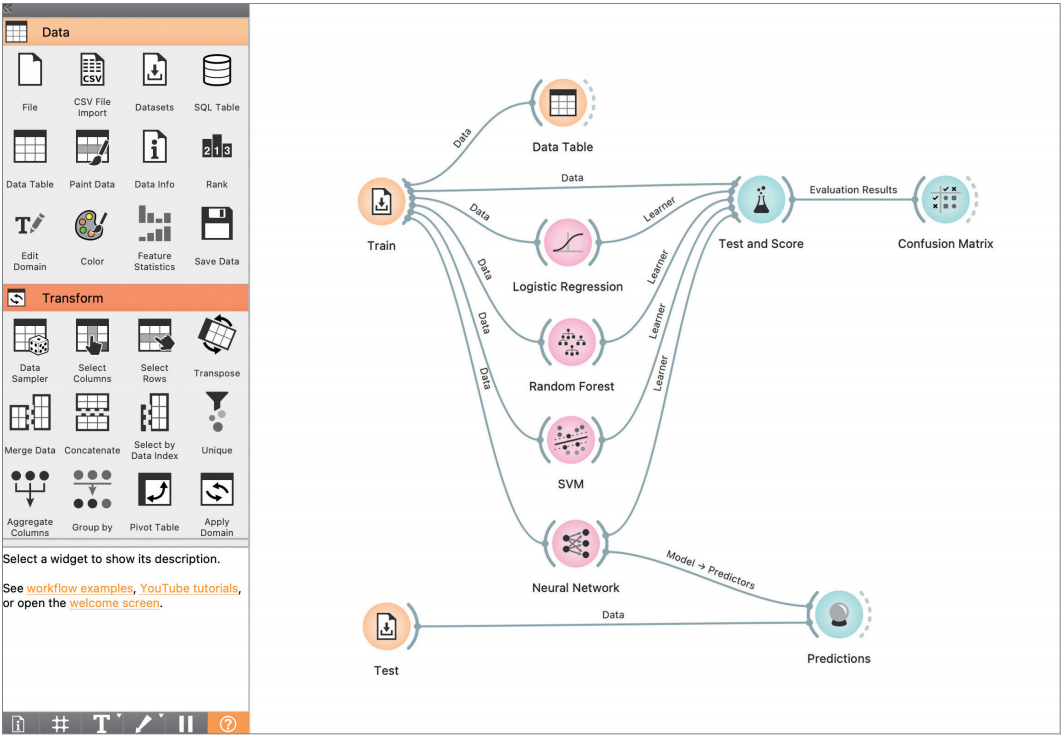
[그림2] Orange3을 이용한 데이터 분석
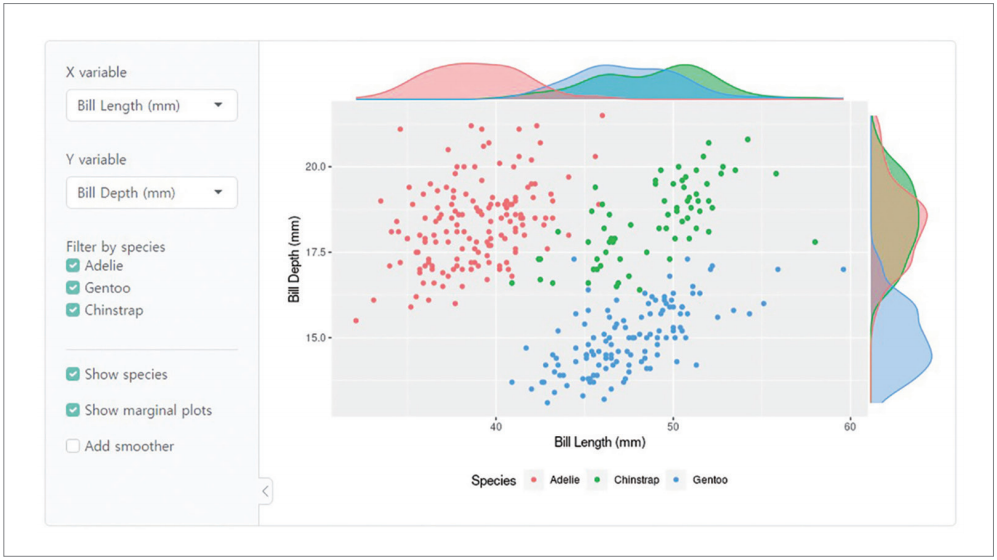
[그림3] Shiny를 이용한 분석결과 시스템화
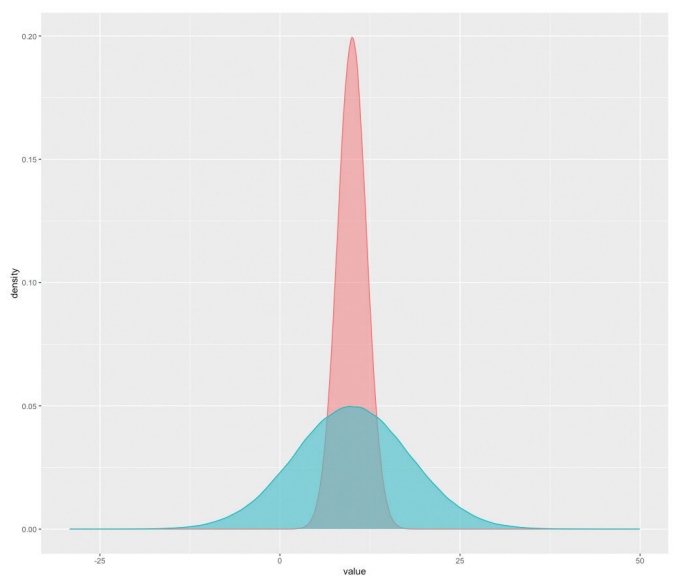
[그림4] 평균과 분산
이쯤에서 통계 리터러시에 관한 이야기를 할 필요가 있다. 데이터분석은 통계에 기반하고 있고 통계의 지원 없이는 데이터 분석 결과에 대하여 확신을 가질 수 없다. 통계학은 수학이나 다른 고전 학문에 비하여 그렇게 역사를 길게 보지 않는다. 아직도 많은 발전이 기대되는 학문으로 해석될 수 있다.
가끔 AI 강의 중 “평균이 무엇인가요?”라는 질문을 던져보면, 대부분 “모든 요소의 값을 더하고 요소의 개수로 나눈 값입니다.”라고 대답한다. 나의 질문은 “What is the mean?”이었지만 대답은 “How to calculate the mean?”에 대한 대답이었다. 그렇다면 정확하게 평균이 무엇이고 어떻게 사용해야 하는지 알지 못하고 있다는 결론에 이르게 된다. 평균과 분산을 이해하는 것은 데이터 분석에서 중요한 요소인데, 정확히 이해를 못 하고 있다는 방증이라고도 할 수 있다.
데이터가 갖고 있는 정보의 양과 분산, 데이터의 대푯값, 데이터의 분포, 데이터 간의 상관관계, 데이터의 차원, 가설 및 검정 등을 이해해야만 데이터 분석 결과를 확신할 수 있기 때문이다. 기술분석은 평균값, 중앙값, 최빈값, 분산, 범위, 분위값, 왜도, 첨도 등을 나열하는 것으로 끝나는 것이 아니기 때문이다. 가끔 공공기관에서 데이터 리터러시 강의를 하면서, 공공에서 발표되는 모든 데이터 요약 자료에 Box Plot 등의 시각화 요소나 기초통계량을 같이 병기하면 리터러시 차원에서 좋을 것 같다고 이야기하곤 한다. 바로 통계 리터러시가 필요하기 때문이다.
[그림5] Box Plot을 이용한 데이터 시각화
데이터도 없고 통계에 대한 리터러시도 낮은 상태에서 AI를 이야기할 수 있을까? 단지 AI 응용시스템의 사용자로 국한한다면 그럴 수도 있다. 그러나 CDS 차원에서 데이터 리터러시, 통계 리터러시는 필수 문해력이라고 할 수 있다. 데이터 리터러시나 통계 리터러시는 그렇게 어려운 주제가 아니다. 데이터의 가치를 이해하고 데이터와 통계에 기반한 과학적인 의사결정이 조직문화로 자리 잡을 수 있다면 어렵지 않게 리터러시를 확보할 수 있다. 모두가 데이터분석전문가가 될 필요는 없다. 그러나 모두가 데이터 리터러시, 통계 리터러시의 역량은 확보해야 하는 시대임은 분명하다.